One-Hot Encoding, Dot Product and Matrices multiplication: The Basics of Transformers
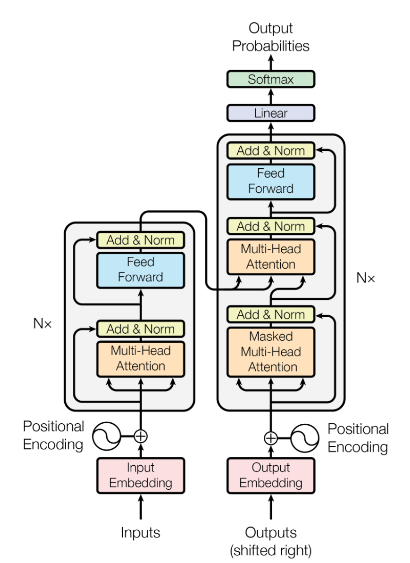
Introduction In the world of natural language processing (NLP), everything begins with words. However, computers don’t understand words directly – they need numbers. Our first task is to convert words into numerical representations so that we can perform mathematical operations on them. This is especially important when building systems like voice-activated assistants, where we need to transform sequences of sounds into sequences of words. To achieve this, we start by defining a Vocabulary, which is the set of symbols (or words) we’ll be working with. For simplicity, let’s assume we’re working with English, which has tens of thousands of words,…



